Real-Time Object Orientation
Bruce Powel Douglass, Ph.D.
Manager of Technical Marketing
I-Logix
Some of the contents of this paper are condensed from the author's forthcoming book, Real-Time UML: Developing Efficient Objects for Embedded Systems, to be published by Addison-Wesley, and the author's course, Real-Time Object-Oriented Analysis and Design, offered through I-Logix.
A couple of decades ago a war was fought-no lives were taken, no territory captured, but it was a war nonetheless. It was a battle for the minds of software developers. Prior to the conflict, software developers jumped in and wrote code, occasionally doing other things along the way. This is the way they were taught in Computer Science classes in school. This was the way their employers expected them to behave. Then along came a radical minority, complete with placards and slogans. Goto Considered Harmful! Design first, then code! The radical notions came about from a different breed. Rather than computer scientists, interested in obscure things like computability, these were software engineers concerned with building real systems that met users needs.
The battle is over and has been for a decade. The upstart "Structured Methods" won hands down. They won because the tenets of structured programming, much like the facilities in the high level languages that predominated in the "High vs. Low Level Language Wars" made it easier to develop bigger programs that were better and had fewer defects. They won because of the Darwinian effect-they were simply better. This is not to say that the old-time coders were wrong-it is true that using structured methods frequently results in programs that are both larger and slower than non-decomposed programs. Monolithic one-procedure programs with lots of gotos can be made faster and smaller than their structured counterparts. Of course, they are also less likely to work, will contain more defects, take longer to develop, and are more fragile during maintenance. Structured methods won because the true need wasn't raw speed or minimal memory-it was to meet the user's requirements in a reasonable time frame, using a finite team of developers on a strict schedule. Within this environment, unstructured development didn't stand a chance.
The same lines have been drawn again, but this time the antagonists are structured programming (now the "old guard") and the new upstart, Object Oriented programming. However, in case you missed it, that war is over too. Object orientation won for exactly the same reasons that structured methods won more than a decade earlier. It makes the development of larger, more complex software simpler, easier to develop, and freer of defects. Does it result in larger programs? Sometimes, but not always. Does it result in slower programs? Again, sometimes, but not in every case.
Real-time developers tend to be the last adopters of any technology
that results in either slower code or larger programs. This does sometimes
happen, depending on a wide variety of factors. Real time systems are the
most general types of programs; that is, "normal" programming is a special
case of real-time systems. This is because real time systems have all the
problems of "normal" systems plus they are typically far more constrained.
They are, by definition, constrained in time. Additionally, they are usually
constrained in recurring cost. This constrains both memory size and processor
power. One can see why bloated, dawdling code is the nemesis of the real-time
systems developer. Object orientation enhances information encapsulation,
distributed processing, and responsibility-driven development. These things
can slow down and enlarge code for exactly the same reasons as structured
methods, but the benefits are nonetheless real. And, as we shall see, there
are ways to minimize the resource hit of using objects in your next real
time system.
Object Orientation: Fundamental Concepts
Object oriented software is really not revolutionary. The basic concepts of structured analysis are all still here: encapsulation, data hiding, abstraction, and divide-and-conquer. Objective systems merely organize a little differently to enhance these more fundamental ideas. Object orientation is not a silver bullet, but does provide a better way to organize software allowing the developer to build better, bigger, and more complex software with less effort.Objects
The fundamental unit of organization of object oriented systems is (surprise!) the object. An object is a real-world or conceptual entity that stands by itself. This means that objects have:- attributes-internal information
- behavior-things that the object can do
- responsibilities-a purpose in the system
- memory-a persistent state internally stored in its attributes
- identity-each object is unique
- "skin"-an interface presented to the world that can be enforced1
- type-the class which defines the possible characteristics of the object
| Characteristic | Value |
| Attributes | Angle between adjacent robotic arm segments
Rate of change of angle (first derivative) |
| Behavior | Orient the sensor so that any current position can be called "zero"
Return the current angle of the arm segment relative to the set zero point on command Return the angular rate of change of the arm segment on command Change report units between radians and degrees Update rate the sensor at different rates and report the new values Check that alarm limits are not violated and raise an alarm when they are Periodically run a self test to ensure proper operation-if the test fails, signal the centralized error handler of the problem |
| Responsibilities | Periodically monitor the arm segment angle for open- and closed-
loop control of the tool at the end of the arm. Alarms if max or min angles are exceeded. |
| Memory | Stores the current and last angle |
| Identity | (memory address) |
| Skin (Interface) | Zero
Get GetRateChange SetUnits (AngularUnitsType NewUnits) SetReportInterval (int TimeInMs) SetAlarmLimits |
| Type | class AngularPositionSensor |
Sometimes developers confuse the terms responsibility, behavior, and interface. An object's responsibilities are the roles it plays in achieving some system behavior. This is implemented by its behaviors. The interface is the defined syntax of how this object receives instructions or requests from other objects. Many of the behaviors will have direct representations in its interface, but not necessarily all. In the sensor object above, you might conceive of a CheckAlarmLimits operation that allows the client of the sensor to force the sensor to check the alarm limits. In this case, however, the sensor is smart enough to check for limit violations of its own accord. The sensor also undergoes a periodic self test to ensure that it is operating properly. If the self test fails, it signals a centralized error handler object to take corrective measures, such as removing power to the actuators of the arm. This behavior is also not explicitly shown in the interface.
Object Types (Classes)
Loosely speaking, the type of an object is its class. All objects of the same class are identical in the attributes they have, their behaviors, and their interfaces. They differ in their identity and the current values of their attributes (which defines their state). In the example above, the robot arm had 3 sensors, each identical. However, each uses a different port or memory location. The values for the angle and rate of change for each is probably different as well. Yet each provides an identical interface-if you know how to talk to one, you know how to talk to all of them.
If the type of an object is a class, then an object is an instance of a class. All objects have all the attributes and behaviors of their class.
Object Relationships
A sensor is a relatively simple object. Complex behaviors can be obtained from simple classes when they collaborate together, much as the cells of a biological organism collaborate together to further the aims of the organism as a whole. The relationships among the objects govern how these collaborations take place. There are four key kinds of object relationships:
- Association
- Aggregation
- Composition
- Inheritance
- Templates and Generics
Association
Associations model a loose kind of relationship. This kind of relationship is appropriate when the lifecycles of the object are not related or when the secondary object is shared among other objects. A flight control computer controls an engine, tail flaps, and wing flaps. The wing flaps and tail flaps in turn use the hydraulic system. In the former case, the engine is really not part of the flight control computer. These are clearly distinct entities. In the latter case, the hydraulic system is shared among the different movable control surfaces of the aircraft.
Aggregation
Aggregation is an ownership relationship. An engine has pistons. A robot arm has sensors. Aggregation is used when one object logically or physically contains others.
Composition
Composition is a strong form of aggregation. It means that there is only a single owner (normal aggregation allows more than one owner for a shared part) and that owner is responsible for both the creation and destruction of the component object. This ownership implies a couple of things. First, it implies that the life-cycle of the owned object is controlled by the owner, so it must be less than or equal to its lifecycle. A desktop computer object is composed of a CPU object and a Display object. Without those things, the desktop computer object is not complete. Further, no other computer can use the CPU or Display objects-they belong solely to the desktop computer. The desktop computer object might also have a modem. The modem is solely owned by the single computer (in this case), but the desktop computer is still a valid computer object without it.
Inheritance
An object is an instance of a type, loosely referred to as its class. For example, my cat Spot is an instance of the class Cat. The sensor between the first and second robot arm segments is an instance of the class Angular_Position_Sensor.
The class diagram below shows how different kinds of sensors are related to each other:
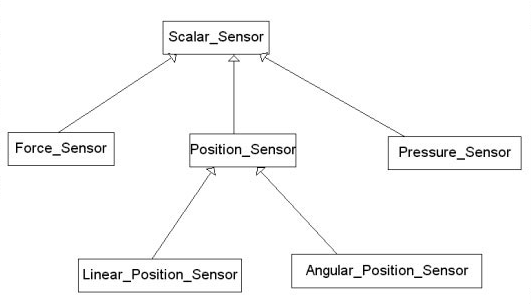
As can other objects, such as the class Input Device:
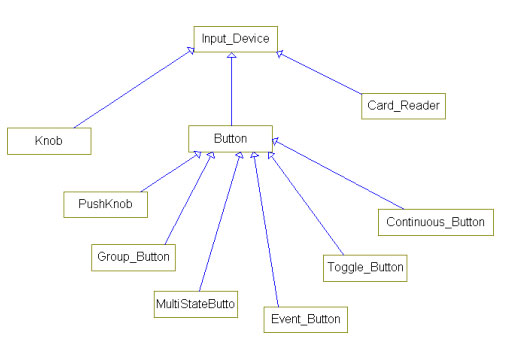
The inheritance relationship is one of generalization-specialization. The parent (or base) class is a more general type than the child (or derived) class. Inheritance is used when you want to specialize behavior. In the example above, there are many kinds of buttons, but each of them is, in fact, a button and has all of the characteristics of a button. For example, all buttons might have a label and issue a Depressed message when it is pushed.
Each specializes the behavior in a specific way. An Event Button sends out an event when the button is pushed; it may have no interesting state, since it has nothing to remember. An elevator call button acts like this. The Continuous button acts slightly differently, continuously sending the Depressed message until it is released, much as a doorbell works. A Toggle button toggles back and forth between two states, such as On and Off, like a light switch. A Multistate Button may have an entire state machine to march through, stepping through the states one by one as the button is repeatedly pressed. A Group Button works like radio buttons on a car stereo-selecting one of a set of buttons selects the pushed button and deselects the rest.
The inheritance relationship is one between classes; one class is the parent of another. This is different than either the Has or Uses relationship which is a relationship between objects; one object uses another.
Creating inheritance in C++ is a very simple matter. Below, a NumericSensor class is defined, and the AngularPositionSensor class is derived from it:
class NumericSensor {
int *Addr; // address of sensor
int value; // sensed value
protected:
virtual void acquire(){ value = *Addr; }
int UpdateRate;
void enableTimer() {
OSEnableTimer((*acquire)(), UpdateRate);
};
void disableTimer() {
OSDisableTimer(((*acquire)());
};
public:
NumericSensor (int *ad, int *TAd) :
Addr(ad), TimerAddr(Tad),
value(0), UpdateRate(1000) { enableTimer(); };
~NumericSensor() { disableTimer(); }
int get() { return value; } // return last acquired
// value
int SetReportInterval (int TimeInMs) {
updateRate = TimeInMs;
enableTimer()
}
};
class AngularPositionSensor : public NumericSensor{
protected:
int lastValue;
virtual void acquire(){ lastvalue = value;
value = *Addr; }
AngularUnitsType Units;
int ReportInterval;
int AlarmLowLimit;
int AlarmHighLimit;
public:
AngularPositionSensor (int *ad, int *TAd) :
sensor(ad, Tad),
lastValue(0) { enableTimer(); };
void zero();
float GetRateChange();
SetUnits(AngularUnitsType NewUnits);
SetAlarmLimits(int Low, int High);
};
In this case, the class Sensor knows how to acquire data and schedule the
acquisition. The AngularPositionSensor class adds some additional behavior,
modifies some original behavior, and keeps some behavior of the sensor
the same. Only code for the new behaviors needs to be written. Note that
AngularPositionSensor still has an attribute called value which it inherited
from its parent class, along with the address of the sensor and some operators.
Templates and Generics
Inheritance is best used when the child class is a specialization of the parent, and the child needs to do something slightly differently or needs additional attributes or behaviors. Generics (templates in C++ terminology) are subtly different. First of all, a generic class is not a true class, but can be instantiated as to create a class. You cannot create an object instance of a generic, only a class instance. This differs from a parent class from which a child inherits, which can be instantiated as a object.
Generic classes provide a different purpose than inheritance. Frequently, you want to use the same kind of thing, and provide the same set of services, in a variety of circumstances. The classic non-objective use of a generic is a sort routine. It frequently happens that you want to sort arrays of all sorts of base types-integers, floats, strings, and user-defined types. In traditional languages, you must write a different sort routine for each base type. A generic sort routine however, is written only once, but instantiated many times, once for each base type of interest. Thus, once you have written a single sort routine, you merely instantiate it for integers, floats, strings, etc.
In object systems, it is often necessary to provide collections of classes, such as collections of bank accounts or sensors, or bus transactions. The semantics of collections are identical for many different base classes, with operations like insert(), remove(), sort(), first(), last(), and next(). Generic classes allow you to write the collection once and then instantiate it for each of the base classes of interest. A simple C++ example is shown below. This collection class holds some number (size) of things (of type class T). For example, the main() function object MyInstSize10Array is a collection that holds up to 10 ints.
template <class T, int size>
class MyArray {
T *collection[size];
int head, tail;
public:
MyArray(): head(0), tail(0) {}
void insert(T *item);
T* remove();
};
template
void MyArray::insert(T *item) {
collection[head++] = item;
head %= size;
}
template <class T, int size>
T* MyArray<T, size>::remove() {
if (head == tail) return 0; // empty
T *result = MyArray[tail++];
tail %= size;
}
class String {
public:
char *ch;
String(char *p = ""): ch(strdup(p)) {}
};
void main() {
MyArray <int, 10> MyIntSize10Array;
MyArray <float, 100> MyFloatSize100Array;
MyArray <String, 15> MyStringSize15Array;
};
In this example, we have written a single template that takes a class type
(the base type of the collection) and an integer value (the size of the
collection). We created three separate classes and one object of each.
The result is that in main() we have three collections that act the same
semantically but they hold different base types, one for ints, one for
floats, and one a user-defined String class.
Generics allow use to provide many classes that serve the same purpose and provide the same operations, but can apply them on different types. This is a powerful facility for creating reusable components.
Exception Modeling
The final feature we will discuss is exception handling. Exception handling is not an object oriented feature per se, but it is present in Ada-83 (an object-based language) and Ada-95 and C++ (both object oriented languages). Exception handling permits the separation of error handling code from the main execution stream. This results in cleaner, more understandable code, both for the exception handling code and the primary program logic. Even more important, exception handling provides the ability to force handling of error conditions. In far too many programs, error conditions are not handled even when they are detected. The standard C idiom is to return error codes as the function return value. However, this error value can be discarded without even being checked, so the language does not enforce error handling on the clients of the functions.
In Ada, exceptions are raised by value. Exceptions are basically a user-extensible enumerated type. If an exception is detected ("raised"), then the current procedure is terminated, and control is passed to the exception handling code of the calling procedure. If it is handled there, the exception handler executes and the calling procedure terminates to its caller and the code continues. If not, then the calling procedure terminates, and its caller is checked to see if it handles the exception, and so on. Control walks back up the procedure call tree until someone handles the exception, or the program terminates.
In C++, exceptions are thrown when detected and caught by exception handling code somewhere up the call tree, much like Ada. Unlike Ada, exceptions may be any type, including object types. Further, they are caught, not by value, but by type. This C++ feature makes it easy to pass additional information in the exception class as needed for exception handling.
Real Time Issues
Real-time software developers have all the problems of non-real-time developers plus several more. Notably,
- Timeliness
- Low Resource Availability
- Memory
- CPU Speed
- Reliability Issues
- Safety Issues
- Compiler and Tool Availability
- Bootstrapping
Timeliness
Timeliness is the key difference in real-time systems. Many people think of real-time as real-fast, but that is a dangerous misconception. As I like to tell people,
In real-time systems, the right answer at the wrong time is the wrong answer!Designers draw a distinction between hard, soft, and firm real time. In a hard real time system, if a processing deadline is missed, the system has failed. The aircraft may crash, the nuclear power plant may explode, or the pacemaker may cause ventricular fibrillation. The definition of correct intrinsically includes "timely." Soft real time systems must meet a deadline but only in the average case. In such systems, it is permissible to be delayed provided that overall, the system performs in a timely fashion. Screen switching is frequently a soft real time requirement-if it happens 250 ms later than expected, no one really cares. Firm real time systems are systems that are primarily soft, but do have a hard deadline as well. Most real time systems contain tasks of all three kinds.
In most hard real-time systems, great effort is expended to ensure deadlines are met. Additional formal analysis, such as rate monotonic analysis, is often done for just this reason. Designs must take the timing into account and additional tests must be developed to demonstrate that the deadlines are met.
System Resources
Desktop systems these days have gigabyte hard disks with megabytes of main memory. The processors themselves run in the 100+ megahertz range. Few embedded real-time systems have this kind of compute power at their disposal , although there are some. Most embedded controllers are small 8 and 16 bit processors with built-in ROM and meager RAM. It is not uncommon at all to have 32K ROM and 1/2 K RAM. This is an endemic situation for embedded systems developers because the computer is shipped as part of the product. As such, it forms a recurring cost item on each and every product shipped. Compared to desktop software, the manufacturing costs of embedded systems are much higher. This produces a strong market pressure to reduce the system resources to a bare minimum.
As desktop computers become more powerful, however, the commodity pricing affects computer hardware including RAM, ROM, CPUs, and supporting chip sets. The clever embedded systems designer can frequently leverage off the tools and hardware used for desktops. Embedded PCs are a very popular real-time platform these days.
Real time systems often have to be optimized before release in order to execute properly within the low resource environment. This optimization takes time and effort and makes real time software more complex.
Reliability Issues
As a general rule, the reliability requirements of real time embedded computers are much more stringent than for desktop computer software. It is a much bigger deal to have to reset your microwave oven (or cardiac pacemaker, or engine control computer) than to reset your desktop. The reliability that is permissible in Windows or Excel just doesn't cut it for real-time systems.
The increased reliability requirements impact the development of real-time software. Typically, a more rigorous development process is called for. This reduces the defects entered into the system. Each of the phases of development-Analysis, Design, and Coding-typically require additional documentation and detailed work to ensure that defects are not slipping through. Testing is usually greatly increased as well, particularly for safety-relevant embedded systems. The net result is that real-time embedded systems take longer and cost more because the systems are more complex and they must be more reliable. You sure wouldn't want your cardiac pacemaker to get "hung" as often as Windows does!
Safety Issues
As the use of software continues to spread to new application environments, it is increasingly used in situations where safety is a primary concern. Medical instrumentation and aircraft control are just two common examples of safety relevant computing devices. Software is being used to control trains, nuclear power plants, and industrial robots. All of these applications have safety concerns.
Safety-related systems are more regulated than other types of systems. TUV's VDE 0801: Principles for Computers in Safety-Related Systems, IEC 1508: Safety Related Systems, and UL's proposed Safety-Related Software are just three such standards. These (and other) documents call out procedures for determining the level of risk and specific methods for ensuring safety depending on the risk level. Meeting these standards (and more to the point, making safe software) doesn't come for free. Safety control measures, such as dual memory storage, use of CRCs, and hardware watchdog timers, don't come for free. They add time, cost, and complexity to the systems.
Compiler and Tool Availability
Desktop developers have a plethora of tools available. The economies of scale have brought the price of high quality compilers down to a few hundred dollars (on PCs) or a few thousand (on workstations). Because the vendors sell thousands of these, each can be made cheaply. The economies of scale don't apply nearly as well to the real-time embedded market. If you are embedding a PC, you have an advantage. Other target platforms, like DSP chips and 8-bit and 16-bit computers, have more specialized tools. They are usually more expensive and buggier, making the lives of embedded developers interesting, if not easy. Additional support tools, such as EPROM burners, Real Time Operating Systems (RTOS), In-Circuit emulators, and oscilloscopes are available to help the developer out. In order to use them, the developer must understand how they work and design his systems to take advantage of these debugging and development tools.
Bootstrapping
One of the things most software developers never have to deal with is controlling how the system starts up. The only ones who worry about this are BIOS, operating system, device driver, and embedded system developers. Controlling the initialization of the computer, writing Power On Self Test (POST) procedures, initializing specialized hardware, loading the operating system off disk or from ROM-all these pleasures are bestowed on the real time system developer.
If you have a disk in your embedded system, then your RTOS can usually be counted on for loading the application code and managing task threads. If you don't have an embedded disk, you might be able to use static RAM, FLASH, or ROM to load the RTOS. Depending on the operating system, some of the bootstrapping code may be provided for you.
Applying OO In Real-Time Systems
We have briefly introduced the fundamental concepts of object orientation and the special concerns of the real time developer. Let us now concern ourselves with using the former to address the latter.
The first thing the RT developer must do is decide what constitutes a solution to the problem. This step is not fundamentally different to what all software developers must do prior to designing the solution. Object oriented methodologies supply 2 major approaches to this initial analysis: object modeling and Use Case Scenario Modeling. These two approaches are not exclusive, and are most often used in tandem.
Object Modeling
The purpose of object modeling is to determine
- the important objects in the system,
- their important characteristics,
- their relationships among each other.
Identify the Noun
Early on in the project, there is some concept or idea of the system being proposed, expressed in the Concept Statement. The Identify the Noun procedure simply takes the concept statement and highlights the nouns. These nouns form a good starting set of objects in the system. Consider the problem statement below:
A software system must control a set of 8 Acme elevators for a building with 20 floors. Each elevator contains a set of buttons, each corresponding to a desired floor, as well as a current floor indicator above the door. On each floor, there are two request buttons, one for UP and one for DOWN. On each floor, above each elevator door, there is an indicator specifying the floor that elevator is currently at and another indicator for its current direction. The system shall respond to an elevator request by sending the nearest elevator that is either idle or already going in the requested direction. Safety interlocks will be handled in hardware.An initial skim of the paragraph reveals the following candidate objects:
- system
- elevator
- building
- floor
- door
- button
- current floor indicator
- request button
- elevator request
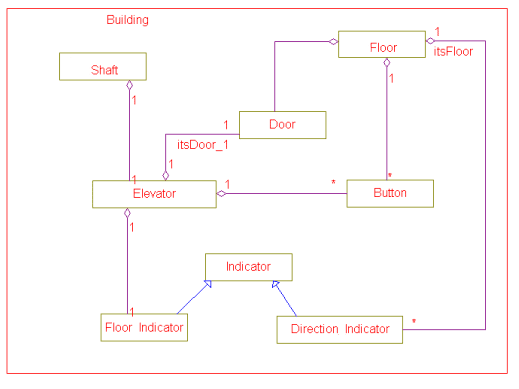
In the class model above, the diamonds on the associations indicate aggregation and the physical containment within the Building class indicates composition. The numbers on the associations show the cardinality-the number of objects that participate in the relationship.
We can see that the building has many ("*") shafts, each of which has one elevator. The building has a number of floors, each of which has many doors (one per shaft, in fact), a number of direction indicators, and 2 elevator request buttons. This class model shows how the different classes of the objects relate to each other.
CRC (Class-Responsibility-Collaboration) cards are another way to initially determine the classes. Using this method, you don't need a CASE tool, but rather use 3x5 cards. Write down the class name on the top of the card and beneath that, its responsibilities. Below that, write the other classes that help the class achieve its responsibilities. As the class becomes elaborated, you can add its attributes and behaviors on the back.
For example, the elevator seems to be a key class here. A CRC card for the elevator might be:
| Elevator | |
| Responsibilities | Accepts requests to go to floors and queues them, and answers
them in a closest-first order. Conveys patrons to their desired floors. |
| Collaborators | Elevator Request Button
Floor Request Button Direction Indicator Floor Indicator Door |
| Attributes | Direction
Current Location Destination |
| Behaviors | Add Destination
Pause Go to next floor Query Location Query Direction Activate Alarm |
With a large enough tabletop and a thick enough pile of blank 3x5 cards, an initial class model for most systems can be created in a few hours. This is an iterative process of refinement. If you find classes that have no responsibilities, you will delete them. As you uncover responsibilities not yet met, add classes to own them. CRC cards are an excellent brainstorming tool, but do not replace a full CASE tool once the initial class structure stabilizes.
Scenarios and Use Cases
Scenarios and use cases allow you to explore the class model. A scenario is a particular sequence of steps through the model of a typical (or atypical) use of the system in question. Scenarios are invaluable as a means to capture the user requirements as well as understand their implications. In a system such as the Acme Elevator System, you might expect several dozen scenarios to capture all the usage requirements. Consider just one:
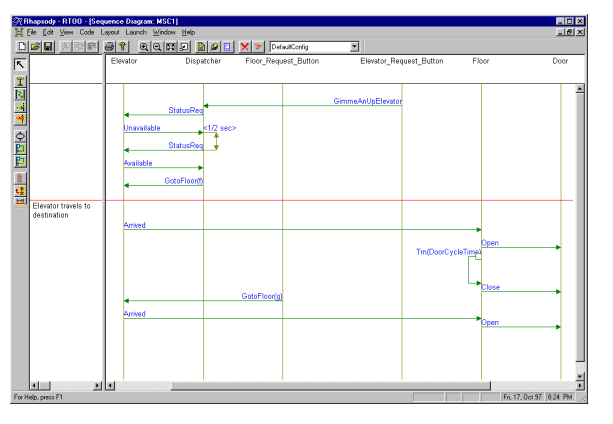
A patron requests an elevator to go down; one is not available going in that direction and they are all in use. The request is queued until an elevator is available for the request.In looking at this scenario, a question pops up-who is going to hold the request until an elevator is available? For that matter, who decides which elevator should handle the request?
There are a number of possible answers. The elevators might arbitrate for the request. Or, the first elevator that checks for new requests could take it. The solution we'll use here is that a new object, the "Dispatcher" owns the responsibility of queueing requests until they can be dispatched, and selecting elevators using some sort of fairness algorithm.
The scenario can be modeled using a sequence diagram:
External Event List
The External Event List is another way to capture the requirements of the system. This is a list of the events that occur in the system's environment that the system must respond to or control. This is usually shown as a table, such as the one below.
| Num | Event | Arrival Pattern | Period or Minimum Interarrival Interval | Response | Object Handling Event | Performance | Source |
| 1 | Patron requests an elevator | aperiodic | 50 ms | Dispatcher tells Elevator to add destination; elevator goes to the floor | Dispatcher | 1 sec | Patron via Elevator Request Button |
| 2 | Patron requests a destination | aperiodic | 50 ms | Elevator adds the destination and goes to the floor | Elevator | 2 sec | Patron via Floor Request Button |
| 3 | Patron pushes alarm button | aperiodic | 50 ms | Audible alarm sounds | Alarm Annunciator | Respond within 250 ms | Patron via Alarm Button |
| 4 | Time to update floor displays | periodic | 1 sec | Each elevator reports its location and direction | Elevator | Respond within 1/2 sec | Floor Indicator |
State Modeling
State modeling is widely used in object oriented systems. The primary difference between the object oriented and the structured use of state models is what the finite state machine represents. In structured methods, the state model is of a "system" or "subsystem", and it is frequently difficult to show exactly how the code matches the state model. In object oriented systems, the state models are of objects and classes and so the matching of state models to code becomes much simpler. Below is a Harel Statechart model of the elevator object. Note that this state model is nested rather than flat. The primary states of the elevator are: Going Up, Going Down, and Idle. The first two primary states are decomposed into substates as well:
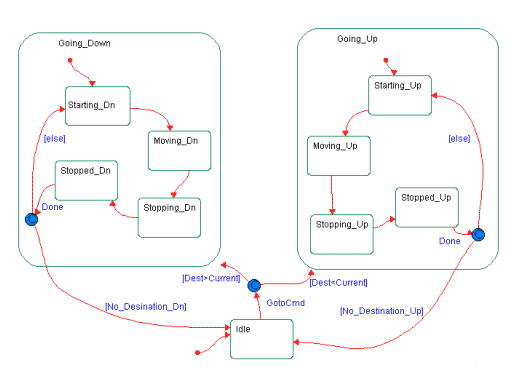
The other objects in the system, such as the dispatcher and the doors,
have their own state machines as well.
Pragmatics
Many pragmatic issues of using object orientation on real time systems development exist, such as:- Selecting a methodology
- Selecting a language
- Selecting a design tool
- Introducing objects into the work environment
- Organizing the development team
- Metrics for project tracking
Methodology
If you're selecting an object-oriented methodology today, your choice is clear. The Unified Modeling Language (UML) is a third-generation design language for specifying complex systems. It is the natural successor to the second generations methodologies, including Booch, OMT (Rumbaugh, et. al.) and OOSE (Jacobson). It represents a substantial effort from a large number of methodologists to construct a common means for describing complex systems using the now mature concepts of object-orientation. Visually, it is reminiscent of OMT in that rectangles represent classes, lines represent associations, and diamonds indicate aggregation, but the visual aspects of the notation are the least significant. The effort of defining the object and class semantics of the underlying UML metamodel was spearheaded by Grady Booch, Jim Rumbaugh, and Ivar Jacobson while the specification of state behavior is strongly based on David Harel's work on Statecharts. However, a great number of people worked on the evolution of the UML and contributed very significantly. The UML is a cooperative effort from dozens of top methodologists and should not be thought of as merely the coalition of three or four individuals. Nor should you be put off by the "design by committee" approach taken. The UML presents the best and most useful set of object semantics from literally centuries of accumulated experience achieved in the last couple of decades.As already mentioned, the UML is a language for the specification of complex systems. It does not include a development process per se2. Process refers to how you use the various features of UML and how and when you link them together during the course of system development. This article will (mostly) limit itself to showing what UML is and leave it to the remaining parts to show how it can be profitably applied.
The UML was originally developed in response to the OMG's call for proposal for a standardized object modeling language. There were other contenders, but given the rigor and robustness of the UML and its broad industry support, the competitors have fallen by the wayside. The goals of the UML are to:
- Provide a common, expressive visual modeling language for capturing object model semantics
- Provide a model with a formal and rigorous semantic basis that doesn't require too much formalism by the user
- Provide a metamodel which may be tailored and extended by the user
- Be independent of programming language and development process
- Encourage the growth and maturity of the OO tools market
- Support the latest in methodological development, including collaborations, design patterns, large scale system development, frameworks, and components
- Integrate best practices culled from the last couple of decades of active OO development and research
Design Tools
Design tools exist to help you design deployable systems that meet all their requirements. This includes logical requirements (what it should do), implementation requirements (how it should do it) and performance requirements (how quickly must it do it). For real-time system developers a design tool should have the following attributes:- Should capture the essential object model including
- Structure-using object diagrams
- Behavior-using scenario and statechart diagrams
- Should produce full behavioral code not just code skeletons to be filled in manually:
- Constructors and destructors
- Thread support including
- Specifying active objects (roots of threads)
- Protection of critical resources with mutex semaphores
- Fully executable code from statecharts
- Code should be retargettable to different platforms and operating systems
- Code should have a small footprint (no virtual machines controlling execution of model)
- Should animate the design model on the host and on the ultimate target system
- Monitor object's state during system execution
- Capture inter-object communication on scenario diagrams during system execution
- Monitor attribute values during system execution
- Allow setting breakpoints and insertion of events during execution
Performance
If you use C++, then you will generally get performance within a few
percent of what you would get if you used C. If you use CLOS or Smalltalk,
your performance will be impacted more significantly. However, in the object
oriented real-time arena, the only major player today is C++ (Ada 95 may
be one soon-time will tell). It is perfectly possible to implement an object-oriented
design in a procedural language, like C, or even assembly. The benefits
of object orientation are most easily achieved, though, when an object-oriented
language is used for implementation. So, let's look at the object-oriented
features and see where they might impact performance. This will allow you
to at least use the features with your eyes open, and perhaps use the features
in a way so that they will not impact the execution speed of your programs.
Polymorphism
In polymorphic systems, it is possible to have the interface of several functions or object methods be identical, even though they all differ in implementation. Polymorphism means that the system can use the type of the parameters to select which method is appropriate. In the simplest case, this allows the developer to design new classes and create operations on them that intuitively make sense-such as creating a matrix class and defining the meaning of the '+' operator on it. However, when combined with inheritance, polymorphism provides a powerful programming tool.Suppose you have a base class called Sensor. Sensor has a method called acquire() which returns the current value of the sensor. Now, you can build a class hierarchy of different sensor types-position sensors, angular position sensors, voltage sensors, pressure sensors, etc. Each of these classes has the method acquire because it is present in the base class, but each probably redefines it because the means of acquisition are internally different. A pointer to an object of type sensor can also point to an object of any descendent class, since each is still a sensor. This means that it is possible to have a base class pointer to a sensor and change the object type to which it points and the correct acquire method will still be called!
Consider the code below:
void main() {
sensor *SensorArray[10];
assignSensors (SensorArray);
for (j=0;j<10;j++) {
cout << SensorArray[j]->acquire();
};
cout << endl;
};
The various elements of the array SensorArray can be any sensor subtype,
yet the statement
cout << SensorArray[j]->acquire();executes the correct version of acquire in each case. If SensorArray[5] points to an AngularPositionSensor object, then SensorArray[5]->acquire calls the method AngularPositionSensor::acquire and not Sensor::acquire.
So now that we understand the feature, what does it cost? The answer ranges from 0 to the cost of one additional pointer dereference. The cost of polymorphism is 0 if the compiler can figure it out. The code
- matrix a,b,c
c = b + a;
The use of the polymorphic acquire method however, cannot be figured out by the compiler ahead of time. In this case, the compiler creates a virtual function table, which is nothing more than a table of function pointers, for each polymorphic operation. The compiler must be explicitly told to do this in C++ with the virtual keyword. When the class sensor is compiled, the compiler creates an additional data member in the class which is a pointer to the virtual function table. When the statement SensorArray[5]->acquire() is called, the compiler inserts code that uses this additional data member as a pointer to the virtual function table using the function number as the index into the table. Thus, you can see that the overhead for virtual functions is a small amount of memory (the extra data member and the virtual function table) and the run-time overhead for an additional pointer dereference.
Because C++ is so concerned with efficiency, this small overhead isn't
added unless you explicitly declare the function as virtual. Other OO languages
only provide late binding, so polymorphism always costs you in those languages.
Run-Time Checking
There are a couple of kinds of type checking. The first is familiar to Pascal programmers. If you use an out-of-range index in an array access or try to assign a value out of range, the Pascal run-time system will detect it and terminate your program. For example
program BadProgram;
var
a: byte;
b: array[1..10] of integer;
begin
b[1] := 256;
a := b[1]; { Error! Out of Range }
a := 0;
b[a] := 15; { Error! Index out of range}
end.
These errors are caught by the Pascal run-time system. This means that
the compiler includes "invisible" code that checks the indexes and assignments.
C, of course, does not. C++ does not either, so the run-time overhead for
range checking is zero.
To build reliable and safe systems, you can add this kind of code yourself. You certainly do not want to write code like this every time you access an array:
// rather than b[j] = 256 if ((j<0) || (j>=10)) catchError(RangeError); else b[j] = 256;Its just too clumsy to write that every time you want to use an array. It is possible in C++, though, to build this feature into an array class so that you can naively use the array like
- b[j] = 256;
The C++ way to do this is to define a safe array class that overloads the array operator square brackets, like this:
class IndexException {
public:
int index;
IndexException(int j): index(j) {};
};
class SafeArray {
int size;
float *p;
public:
SafeArray(int SetSet) : size(SetSize) {
if (s>0) then
p = new float(size);
else
throw IndexException(size);
};
float & operator [] (int index) {
if ((int >= 0) && (int < size) )
return p[index];
else
throw IndexException(index);
}
~SafeArray() { delete p[]; }
}
This code first defines an exception for when an index is out of range
and carries the index back up the call tree to the handler. The SafeArray
class itself is created with a number of elements to allocate. If the index
accessing the array later with the [] operator is not in the valid range,
the class throws an exception. Every user of the class need not catch the
exception nor check for the violation. Separate error handling code can
take care of the infraction without overwriting crucial code or the operating
system (the C way) or terminating the program immediately (the Pascal way).
The other kind of run-time checking occurs when you are using polymorphic operations in a backwards way. It is always safe to do an upcast-that is, it is always safe to treat an object as if it were an object of its parent class. Since it is impossible to exclude attributes or operations as you derive child classes, you are guaranteed that the parent's data and function members exist in the child class.
What is not always safe is the downcast. In a downcast, you have a pointer to a parent class, and you treat it as if it were a child class. Since the child class may have added data or function members, if the object is not really of the child class, you may be calling code that doesn't exist. This is always a bad idea!
class a {
public:
int x;
void f(void);
}
class b: public a {
public:
float y;
int g(int t);
}
void main(void) {
a *aPtr;
a MyA;
b MyB;
aPtr = &MyB;
aPtr->x = 3; // upcast -- always ok.
aPtr = &MyA;
aPtr->y = 3.14159; // downcast! Bad!
}
The solution that C++ provides is called Run Time Type Identification (RTTI).
The typeid operator returns the type making for a safe downcast:
void main(void) {
a *aPtr;
a MyA;
b MyB;
aPtr = &MyB;
aPtr->x = 3; // upcast -- always ok.
aPtr = &MyA;
if (typeid( *aPtr ) == typeid( b ) )
aPtr->y = 3.14159; // downcast! checked!
else
cout << "no can do!" << endl;
}
Naturally, this feature doesn't come for free and requires a small amount
of additional memory to be added to each class that holds the type identification
so that it can be queried. Some compilers allow you to disable RTTI and
save the overhead, but this usually means disabling exception handling
as well.
Object Creation and Destruction
Objects are created via constructors and removed via destructors. Objects that have no data members and no virtual functions use no memory, other than the memory for the executable code of the member functions. All objects have a default constructor, if you do not explicitly create one for the class. If there are virtual functions, it will automatically create the virtual function table and a pointer to it. Further, the constructors of the base classes are called as well, since each derived class is also an instance of the base class. This has the advantage in that it is possible to guarantee that memory used by a class will always be released (see below).
Templates / Generics
Templates instantiate into classes which can then be instantiated as objects. The run-time overhead for this is 0, since it is handled by the compiler. However, the compiler probably generates the classes as if you manually declared each one as a separate class. This means that the executable code is possibly duplicated for the templates. This can be circumvented through judicious mixing of inheritance and templates.
Watch the Copy Constructor!
In C++, it is very easy to create anonymous copies of objects in the process of executing statements. These anonymous objects are destroyed fine, but the creation and destruction of these objects does take time. Consider the use of j++ instead of ++j. j++ makes a copy of the object j and then destroys it-the compiler does this because the old value of j must remain around until the statement is completed. ++j immediately discards the old value, so a copy need not be made. For the same reasons, it often makes sense to create +=, -=, *=, and /= operators, since they don't have to work on temporary objects.
It pays to really understand the rules of construction if you're going
to use C++ on a real time system.
Exceptions
Exception handling is a good thing to have in a system. Exceptions provide a strong mechanism that allows some portion of your system to identify error conditions knowing that they can't be ignored by other portions. Exceptions have been used successfully for more than a decade by Ada programmers in a wide variety of real time systems. C++ also now sports exceptions as well.Exceptions don't come for free, however. Exception handling works in the following way: some executable code, written either by the programmer or by the compiler, identifies an error and throws it (using C++ terminology). This results in immediate termination of the current execution block (by immediate, I mean that all properly constructed objects within the scope are destroyed by calling their destructors, and the current scope is ended). The caller of the executable code left its return address on the stack. That address is invoked, then the exception looks in the caller's code for an exception handler. If it finds one that meets the criterion for the exception, it is executed. If not, that block is exited, and its caller is invoked, and so on. The system walks back the stack looking for a handler that can take care of the thrown exception. If one isn't found, the program ultimately exits.
Exceptions typically have low overhead unless you call them. That is, if you do not throw an exception, the overhead for having the ability to do so is small-3% has been quoted for one popular compiler. On the other hand, if you reserve space on the stack for returning error codes (the "C way"), then there is a small performance hit for that as well. If you do throw an exception, the cost is high, since walking the stack backwards can be time consuming.
Note that if an exception is thrown when another exception is pending, the terminate() function is called immediately. Since destructors may be called as a result of an exception being thrown, destructors should never throw exceptions and they must catch all exceptions that might be thrown by routines that they call. Again, since raw pointers do not have destructors, they should also be avoided in any system that uses exceptions.
Inlines
C++ provides an inline directive. This allows the developer to trade off run-time memory usage for additional speed. In the class below, the get method doesn't do much. If it weren't an inline, it would invoke a function call overhead every time a client used it. By prepending the inline directive, the code will be pasted in every place the method is actually called, so the overhead for the function call is removed. The cost is possible code expansion, since the function body may be larger than the function call.
class a {
int v;
public:
int get();
}
inline int a::get() { return v; }
void main(void) {
a MyA;
int c;
c = MyA.get(); // function body copied here
}
Be aware that the inline directive is a suggestion to the compiler, not
a command. The compiler may choose to ignore the directive if it thinks
the function is too complex. Also remember that too much inlining can cause
dramatic increases in the size of your executables.
Overall...
In general, object oriented features can be made as fast as structured programs, or at least close. Anecdotal evidence suggests that although the certain language features are slightly slower, overall C++ programs tend to be well within 10% of their C counterparts. The use of object-oriented techniques frequently results in a better design, which can sometimes make the object-oriented version even more efficient than the structured alternative. The Booch components scaled down from 200K lines of Ada to 30K lines of C++. It is frequently true that bad performance is due to bad design. Proper understanding of how to use the language can help in performance tuning-such as the use of ++j rather than j++ when you don't need the old value of j.
Memory Issues
C++ may use memory in surprising ways if you don't understand the internal mechanisms.
Memory Fragmentation Avoidance
Fragmentation occurs when the use of new and delete causes "holes" in memory to appear that are of different sizes. It can occur that the total amount of memory is more than adequate for an application, but it is fragmented into pieces smaller than is currently needed. This is a real problem for real time systems developers because such systems may have to run continuously for long periods of time-years even, for pacemakers and spacecraft.
Some object-oriented languages don't have memory fragmentation problems. When memory goes out of scope, it is lost until the system decides to clean up memory. This process is called garbage collection, and all other processes must typically halt as memory objects are moved into a compacted space and the unclaimed memory is coalesced into a single large block. Because of this, real time systems usually avoid such languages (such as Java and Smalltalk) like the plague.
The simplest, and most draconian, approach is to allocate all objects when the program begins. That doesn't solve the entire problem, but it mitigates it greatly. You still must concern yourself with the creation of temporary objects. With sufficient understanding of the language, you can minimize the number of temporary objects.
A more reasonable approach is to overload the new operator. This allows you to create your own memory allocation scheme that allocates fixed sized blocks. Since the blocks are all the same size, fragmentation has no effect-all blocks are big enough to fit all objects. If this can't be made to work for your problem, then you can create a new operator that keeps a small number of fixed-block-size heaps around. Most RTOSes provide OS services calls for this, and in any event, it can be written by the application developer if necessary.
Constructors and Destructors
If memory is used, particularly if the memory is dynamically allocated from the heap using the new operator, then the destructor has the responsibility of releasing that memory to the system with the delete operator. This does mean that it is possible to ensure that memory is always cleaned up and memory leaks are plugged. This is a well-known problem with C, because it is possible to allocate memory and have the pointer to that memory go out of scope (and be destroyed) without deallocating the memory. Do this enough times, and your program will halt.
Conclusion
Question: Does OO apply to RT Systems? Yes!
We have ever so briefly touched on using object orientation in real time systems. Object orientation offers a superior way to logically construct programs to improve abstraction, encapsulation, and reuse. Object models more closely reflect the user problem domains and so are more understandable. The special concerns of real time systems-timeliness, performance, reliability, safety, and resource usage-are a good fit for object solutions. Some real time designers are concerned about possible overheads, but if C++ is used, the performance hit is minimal. On the other hand, time spent really understanding how C++ generates object code will be time well spent for the real time developer.
About I-Logic
I-Logix Inc. is a leading provider of application development tools and methodologies that automate the development of real-time embedded systems. The escalating power and declining prices of microprocessors have fueled a dramatic increase in the functionality and complexity of embedded systems-a trend which is driving developers to seek ways of automating the traditionally manual process of designing and developing their software. I-Logix, with its award-winning products, is exploiting this paradigm shift. I-Logix technology supports the entire design flow, from concept to code, through an iterative approach that links every facet of the design process, including behavior validation and automatic "production quality" code generation. I-Logix solutions enable users to accelerate new product development, increase design competitiveness, and generate quantifiable time and cost savings. I-Logix is headquartered in Andover, Massachusetts, with sales and support locations throughout North America, Europe, and the Far East. I-Logix can be found on the Internet at www.ilogix.com
1 This is where a less resourceful author would make some pithy comment about "bleeding edge technology."
2 Ivar Jacobson is coming out with a process book called The Objectory Software Development Process (Addison-Wesley, Spring 1998). My book, Real-Time UML: Efficient Objects for Embedded Systems (Addison-Wesley, December, 1997) also includes material on software development process for real-time systems.